






Job
Company
Salary
Applicant Insights
Employment type
- Full Time
Seniority
Similar Jobs
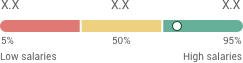
To see more jobs that fit your career
Jobs and employment for Iranian
professionals.
Employment type
Seniority
Similar Jobs
Jobs and employment for Iranian
professionals.