




Job
Company
Salary
Applicant Insights
Employment type
- Full Time
Job Category
Educations
Seniority
Similar Jobs
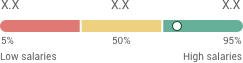
To see more jobs that fit your career
Jobs and employment for Iranian
professionals.
Employment type
Job Category
Educations
Seniority
Similar Jobs
Jobs and employment for Iranian
professionals.