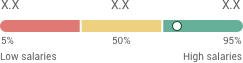Requirements
● Advanced working SQL knowledge and experience working with relational databases, query authoring (SQL) as well as working familiarity with a variety of databases.
● Experience building and optimizing ‘big data’ data pipelines, architectures, and data sets.
● Experience performing root cause analysis on internal and external data and processes to answer specific business questions and identify opportunities for improvement.
● Strong analytic skills related to working with unstructured datasets.
● A successful history of manipulating, processing, and extracting value from large disconnected datasets.
● Working knowledge of message queuing, stream processing, and highly scalable ‘big data’ data stores.
● More than five years of related experience.
● Bachelor's or Master's degree in Computer Science, Statistics, Informatics, Information Systems, or other fields.
● Experience with big data tools: Hadoop, Spark, Kafka, etc.
● Experience with relational SQL and NoSQL databases, including Postgres and Cassandra.
● Experience with data pipeline and workflow management tools: Azkaban, Luigi, Airflow, etc.
● Experience with AWS cloud services: EC2, EMR, RDS, and Redshift.
● Experience with stream-processing systems: Storm, Spark-Streaming, etc.
● Experience with object-oriented/object function scripting languages: Python, Java, C++, Scala, etc.